| I l@ve RuBoard |
|
Methods and JIT CompilationThe CLR executes only native machine code. If a method body consists of CIL, it must be translated to native machine code prior to invocation. As discussed briefly in Chapter 1, there are two options for converting CIL to native machine code. The default scenario is to postpone the translation until sometime after the component is loaded into memory. This approach is called just-in-time (JIT) compilation, or JIT-compiling for short. An alternative scenario is to generate a native image when the component is first installed on the deployment machine. This approach is called precompiling. The CLR provides a deployment tool (NGEN.EXE) and an underlying library (MSCORPE.DLL) to generate native images at deployment time. When NGEN.EXE and MSCORPE.DLL generate a native image, it is stored on disk in a machine-wide code cache so that the loader can find it. When the loader tries to load a CIL-based version of an assembly, it also looks in the cache for the corresponding native image and will use the native machine code if possible. If no suitable native image is found, the CLR will use the CIL-based version that it initially loaded. Although generating native images at deployment time sounds attractive, it is not without its downsides. One reason not to cache native images on disk has to do with code size. As a rule, native IA-32 machine code is larger than the corresponding CIL. For a typical component, the application in its steady state is likely to use only a small number of methods. When the CLR generates a native image, the new DLL will contain the native code for every method, including methods that may never be called or, at best, are called only occasionally, such as initialization or termination code or error-handling code. The inclusion of every method implementation causes the overall in-memory code size to grow needlessly. Worse, the placement of individual method bodies does not take into account the dynamics of the running program. Because one cannot change the method locations in the NGEN.EXE-generated image after the code is generated, each of the handful of needed methods may wind up occupying a different virtual memory page. This fragmentation has a negative impact on the working set size of the application. A second issue related to caching native images has to do with cross-component contracts. For the CLR to generate native code, all types that are used by a method must be visible to the translator, because the native code must contain nonvirtualized offsets a la classic C, C++, COM, and Win32 contracts. This cross-component dependency can be problematic when a method relies on types in another component because any changes whatsoever to the other component will invalidate the cached native code. For that reason, every module is assigned a module version identifier (MVID) when it is compiled. The MVID is simply a unique identifier that is guaranteed to be unique for a particular compilation of a module. When the CLR generates and caches a native image, the MVID of every module used to generate the native image (including those from external assemblies) is stored with the native code. When the CLR loader tries to load a cached native image, it first checks the MVIDs of the components used during the CIL-to-native generation process to verify that none of them has been recompiled. If a recompilation has taken place, the CLR ignores the cached native image and falls back to the version of the component that contains CIL. If a native image cannot be found in the cache (or is stale because of recompilation of dependencies), the CLR loads a CIL-based version of the component. In this scenario, the CLR JIT-compiles methods just before they are first executed. When a method is JIT-compiled, the CLR must load any types that the method uses as parameters or local variables. The CLR may or may not need to JIT-compile any subordinate methods that are to be called by this method at that time. To understand how JIT compilation works, let's examine a small amount of grunge code. Recall from the discussion of casting in Chapter 4 that the CLR allocates an in-memory data structure for each type that it initializes. Under version 1.0 of the CLR, this data structure is internally called a CORINFO_CLASS_STRUCT and is referenced by the RuntimeTypeHandle stored in every object. On an IA-32 processor, a CORINFO_CLASS_STRUCT has 40 bytes of header information followed by the method table. The method table is a length-prefixed array of memory addresses, one entry per method. Unlike those in C++ and COM, a CLR method table contains entries for both instance and static methods. The CLR routes all method calls through the method table of the method's declaring type. For example, given the following simple class, the call from Bob.f to Bob.c will always go through Bob's method table.
class Bob {
static int x;
static void a() { x += 2; }
static void b() { x += 3; }
static void c() { x += 4; }
static void f()
{ c(); b(); a(); }
}
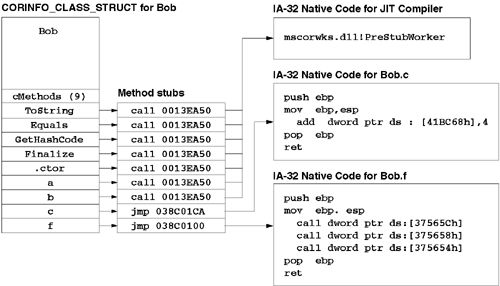
In fact, the native IA-32 code for Bob.f would look like this: ; set up stack frame push ebp mov ebp,esp ; invoke Bob.c through method table call dword ptr ds:[37565Ch] ; invoke Bob.b through method table call dword ptr ds:[375658h] ; invoke Bob.a through method table call dword ptr ds:[375654h] ; clean up stack and return pop ebp ret The addresses used in the IA-32 call instructions correspond to the method table entries for Bob.c, Bob.b, and Bob.a, respectively. Every entry in a type's method table points to a unique stub routine. Initially, each stub routine contains a call to the CLR's JIT compiler (which is exposed via the internal PreStubWorker routine). After the JIT compiler produces the native machine code, the JIT compiler overwrites the stub routine, inserting a jmp instruction that jumps to the freshly JIT-compiled code. This means that the second and subsequent calls to the method will not incur any overhead other than the single jmp instruction that sits between the call site and the method body. This technique is extremely similar to the delay-load feature added to Visual C++ 6.0. This feature was completely explained by Matt Peitrek and Jeff Richter in two articles in the December 1998 issue of Microsoft Systems Journal. Figure 6.1 shows our simple C# class as it is being JIT-compiled. Specifically, this figure shows a snapshot of Bob's method table during a call to Bob.f after f has called Bob.c but before f has called b or a. Note that because the Bob.c method has already been called, the stub for c is a jmp instruction that simply passes control to the native code for Bob.c. In contrast, Bob.a and Bob.b have yet to be called, so the stub routines for a and b contain the generic call statement that passes control to the JIT compiler. Figure 6.1. JIT Compilation and Method Tables
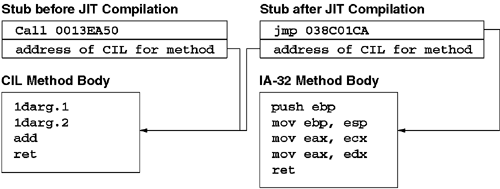
Technically, Figure 6.1 doesn't tell the whole story. Specifically, each method stub initially contains both a call statement and the address of the specific method's CIL. The method stub calls into a small amount of prolog code that extracts the address of the method's CIL from the code stream and then passes that address to PreStubWorker (the JIT compiler). Figure 6.2 shows this process in detail. Figure 6.2. Method Stub before and after JIT Compilation
That single jmp instruction may have performance wonks concerned. However, the level of indirection provided by the extra jmp instruction allows the CLR to tune the working set of an application on-the-fly. If the CLR determines that a given method will no longer be needed, it can "pitch" the native method body and reset the jmp instruction to point to the JIT routine. Conceivably, native method bodies could even be relocated in memory to put frequently accessed methods in the same (or adjacent) virtual memory pages. Because all invocations go through the jmp instruction, making this change requires the CLR to rewrite only one memory location, no matter how many call sites refer to the relocated method. |
| I l@ve RuBoard |
|